Impuls¶
GitHub | Documentation | Issue Tracker | PyPI
Impuls is a framework for processing static public transportation data. The internal model used is very close to GTFS.
The core entity for processing is called a pipeline, which is composed of multiple tasks that do the actual processing work.
The data is stored in an sqlite3 database with a very lightweight wrapper to map Impuls’s internal model into SQL and GTFS.
Impuls has first-class support for pulling in data from external sources, using its resource mechanism. Resources are cached before the data is processed, which saves bandwidth if some of the input data has not changed, or even allows to stop the processing early if none of the resources have been modified.
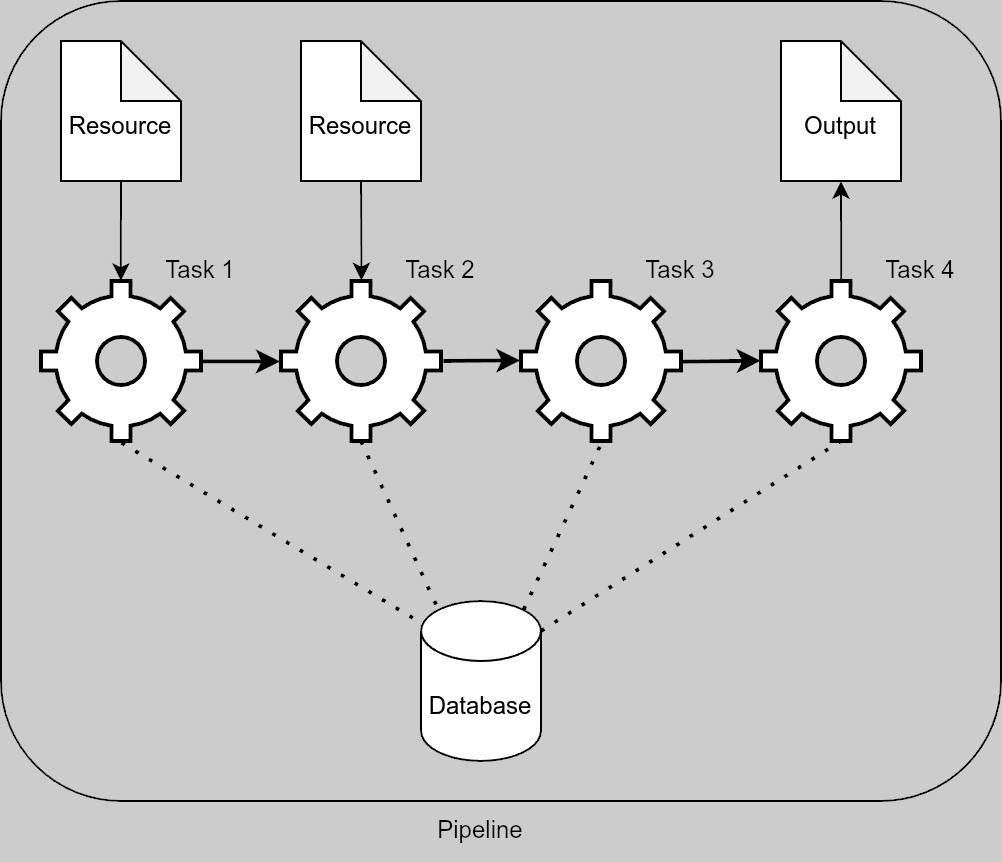
Diagram of basic data-processing components of Impuls¶
A module for dealing with versioned, or multi-file sources is also provided. It allows for easy and very flexible processing of schedules provided in discrete versions into a single coherent file.
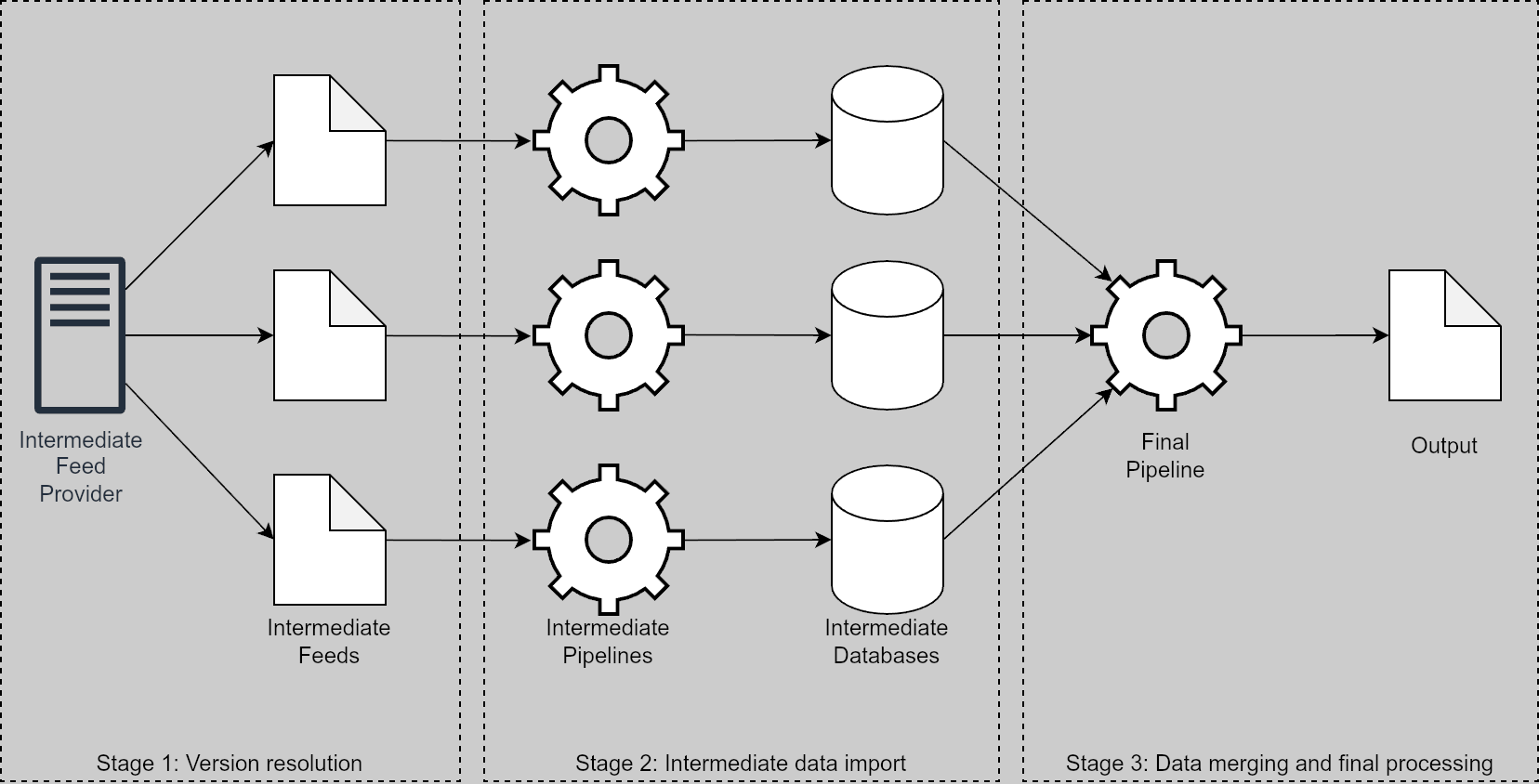
Diagram of multi-file/”versioned” data-processing in Impuls¶
Installation¶
Impuls is published on PyPI. Install by running
pip install impuls inside of a venv.
Impuls comes with a pre-compiled shared library for performance-critical tasks. Wheels are Python implementation and version agnostic, and are available for most common platforms (glibc Linux, musl Linux, MacOS, Windows; both x86_64 and ARM64). Installing on other platforms necessitate compilation form scratch, and for that zig needs to be installed.
Table of Contents¶
- Database Schema
- Example Usage
- API Reference
- impuls
- impuls.db
- impuls.errors
- impuls.model
- impuls.multi_file
- impuls.resource
- impuls.tasks
- impuls.tasks.merge
- impuls.tasks.modify_from_csv
- impuls.tools.geo
- impuls.tools.logs
- impuls.tools.iteration
- impuls.tools.machine_load
- impuls.tools.polish_calendar_exceptions
- impuls.tools.strings
- impuls.tools.temporal
- impuls.tools.testing_mocks
- impuls.tools.types
- License